
Mauve 👁💜 @mauve@mastodon.mauve.moe
- Pronouns
- they/them/it
- mauve+fedi@mauve.moe
- Matrix
- @mauve:mauve.moe
- Github/Gitlab/Discord
- @RangerMauve
Mod
Occult Enby that's making local-first software with peer to peer protocols, mesh networks, and the web.
Exploring what a local-first cyberspace might look like in my spare time.
Joined Apr 2022
Mauve 👁💜
boosted

Earlier this year, I became aware of STANDARD EBOOKS, a donation-dependent group of edtiors and layout experts who have been doing the amazing work of taking out-of-copyright books, turning them into top-quality ebooks, and then releasing them for free.
Some of the books they've done are in the Internet Archive here:
https://archive.org/details/standardebooks
They're seeking 75 patrons in December to keep themselves afloat, consider donating to this amazing cause.
Mauve 👁💜
boosted

With complexity dissolving into chaos so frequently, authoritarian simplicity looks appealing to too many.
You know what’s a great antidote to authoritarian tendencies?
✨Giving many people real power. ✊
What are the biggest obstacles to sharing power in your communities, organizations, or teams?
Mauve 👁💜
boosted

my hands keep slipping and making distributed systems
Mastodon is like if twitter was tumblr
Here's a cool example I just got working.
The data here is being represented with a single array of strings, but the schema can expose it as a Map where the array is split into tuples.
Your application can say `{op: 'add', path: '/Goodbye', value: 'Cruel World'}`, and IPLD can find where in the array that keypair is, update it, and save the IPLD data back in the tuple form. That way you can avoid having to find the array index for your tuple entirely!
https://github.com/RangerMauve/js-ipld-url-resolve/blob/initial-patch/test.js#L230
Tl;dr IPLD lenses make it easier to work with data at the application layer while giving you hatches to optimize encoding and to use more advanced data layouts.
This is important for structured linked data in p2p systems where otherwise you'd need to manually write code to work with all these use cases. With IPLD you can think about schemas for your data, pathing over those schemas, and using patch operations on your schema'd data without needing to worry about the details.
The savings on readability grow larger and larger as your underlying data becomes more nested.
It's a lot easier to work with a path like `/foo/bar/baz/fizzbuzz/` than it is `/12/44/a/0/`.
This applies even more so for advanced data structures like HAMTs or Prolly Trees where an individual segment in the path could actually be a traversal over several nodes in the tree due to their multi-block structure.
E.g. you can have a struct that looks like this:
```
type Foo struct {
foo String
bar Int
} representation tuple
```
Note the "representation tuple" bit.
In your application you can refer to this data using something like `{foo: 'hello', bar: 1337}`, and then on disk it can be encoded to `['hello', 1337]`. (saving you some precious bytes).
This also means you can have a patch that looks like `{op: "replace", path: "bar", value: 666}` instead of `{op: "replace", path: "1", value: 666}`
This is really interesting when you combine it with other IPLD tooling like pathing and patch.
You can use schemas to transform data as you're pathing over it so you can use human readable names for path segments while keeping the lower level data compact.
On top of that you can use the more human readable structures and paths for patching data in a schema'd node. So instead of saying "change the properly deep in this mess of nested lists like" you can say "set foo/bar to 123".
This is really useful with for example IPLD Schemas where you can have "representations" of data use more compact encodings like tuples where you can omit any property names, but have the schema "wrap" over the underlying data to add properties. Then you can "unwrap" the schema'd data to get the "substrate" to encode back into bytes and link to.
IPLD lenses are really underappreciated.
At it's core, IPLD gives you a way to turn data in memory into determenistic encodings in bytes, and then convert that to a Content IDentifier which you can use as links from other IPLD data.
However, on top of that is the concept of "lenses" where you can wrap an IPLD tree in some sort of code that transforms how it looks to code, while still having the same substrate.
Been reading Gideon the Ninth and it's spooky fun
gpt, ai
One of the interesting things (derogatory) about chatgpt is that a lot of people don't seem to get that it's function is to predict text tokens. Often they end up assuming it has some sort of rich reality that it inhabits when you're not asking it things.
E.g. a lot of folks in the comments of this thread are having trouble grasping that it's making up the HTTP responses based on training data and assuming that it's actually making requests.
https://www.engraved.blog/building-a-virtual-machine-inside/
tech rambling
One thing that irks me about how a lot of tech uses infinitely scrolling "timelines" and the such is that most apps don't keep track of your progress if you navigate away.
If I'm viewing something I probably want to keep going from where I left off unless I explicitly want to go to the top.
RSS readers, Google's podcast thing, Mastodon Web (twitter in general), etc.
At least browsers sometimes preserve the scroll for me if it's a full page navigation. 🤷
The fastest computations are the ones you don't need to make.
Mauve 👁💜
boosted
@resuna @tommorris i said before that AI can simulate a dev who can talk their way past the interview and doesn't know what they're doing
Mauve 👁💜
boosted

Finally got a chance to play with @capyloon
Really cool that can so easily develop for it right on the desktop.
Mauve 👁💜
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
just published an update on the #cabal side of things, including news on the nlnet grant we secured and are just starting work on! :>
{kind=link}
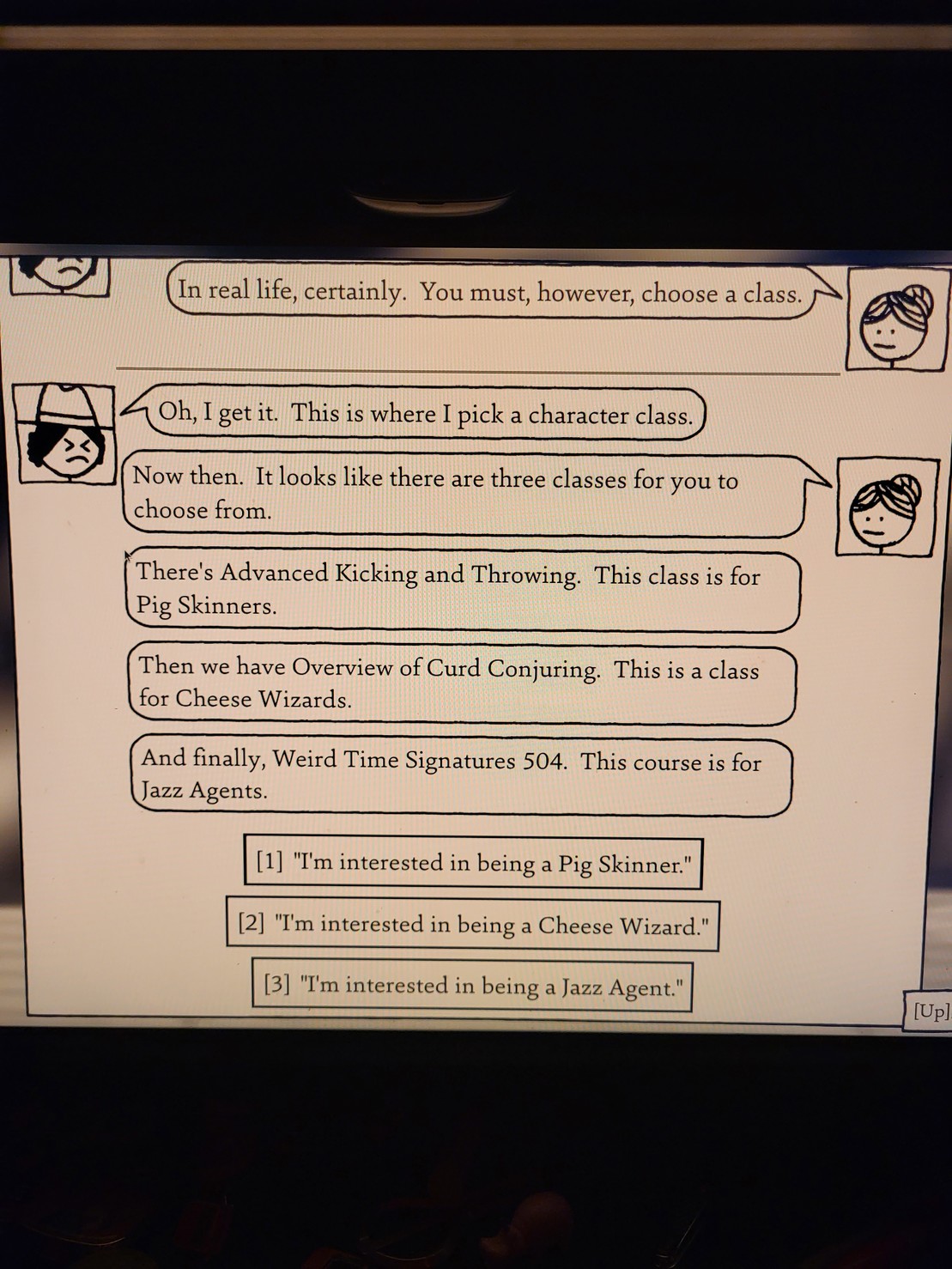
I decided to become a cheese wizard with a minor in insectology
{kind=link}
- Pronouns
- they/them/it
- mauve+fedi@mauve.moe
- Matrix
- @mauve:mauve.moe
- Github/Gitlab/Discord
- @RangerMauve
Mod
Occult Enby that's making local-first software with peer to peer protocols, mesh networks, and the web.
Exploring what a local-first cyberspace might look like in my spare time.
Joined Apr 2022
