
Mauve 👁💜 @mauve@mastodon.mauve.moe
- Pronouns
- they/them/it
- mauve+fedi@mauve.moe
- Matrix
- @mauve:mauve.moe
- Github/Gitlab/Discord
- @RangerMauve
Mod
Occult Enby that's making local-first software with peer to peer protocols, mesh networks, and the web.
Yap with me and send me cool links relating to my interests. 👍
Joined Apr 2022
Mauve 👁💜
boosted

@lutindiscret @peersky @agregore That could be done via an extension pretty easily. Do you want a pre-selected set of languages to translate to or just a prompt to pop up for you to fill in?
@ellyxir yes, when I'm following along on the GPS :P
Mauve 👁💜
boosted

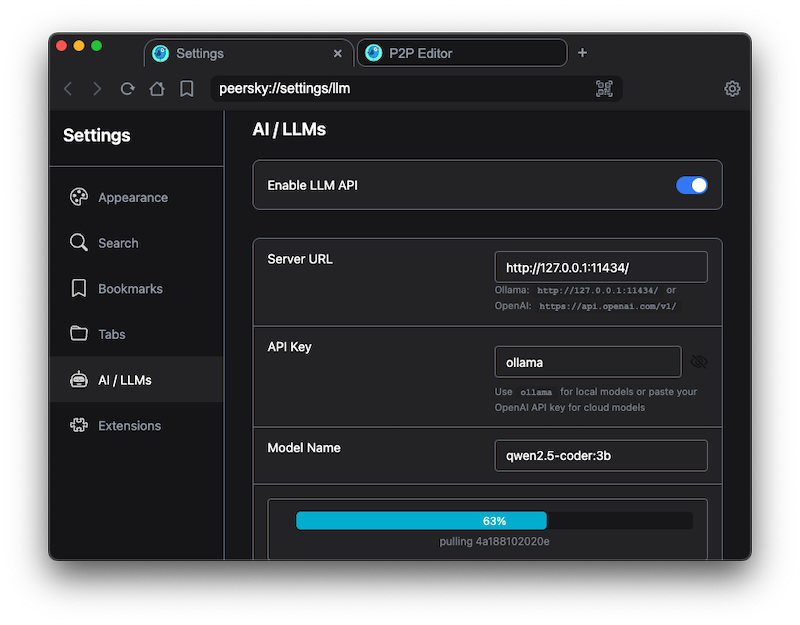
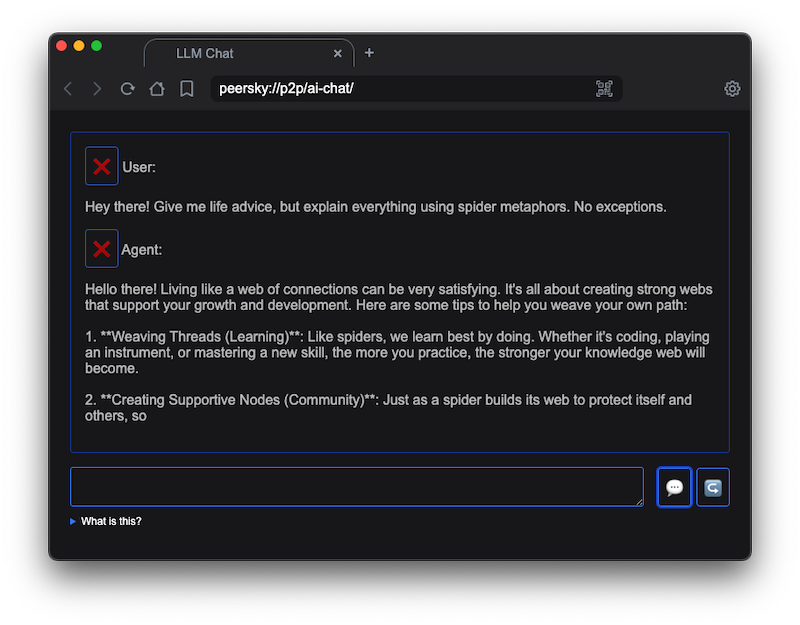
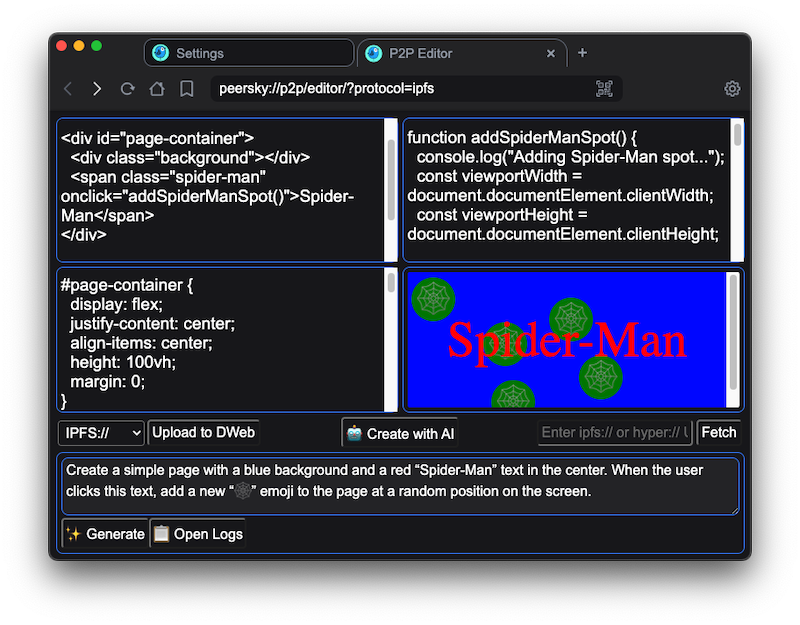
🤖 v1.0.0-beta.15: Local LLMs!
You can now configure local LLM models in peersky://settings/llm
It comes with Qwen2.5-Coder 3B as the default model.
The APIs are currently available to apps such as peersky://p2p/editor/ and peersky://p2p/ai-chat/
Thanks to @agregore and @mauve for the support!
Docs: https://github.com/p2plabsxyz/peersky-browser/blob/main/docs/LLM.md
What’s next?
https://github.com/p2plabsxyz/peersky-browser/issues/97
I'm more effective than google maps' routing. 🤷 Not by much, but it counts!
mildly lewd humor? (unfunny)
She model my language till I'm large 🤖
Mauve 👁💜
boosted

are you fucking kidding me
Due to how my keybinds work I sometimes accidentally trigger my speech to text engine. My test phrase for seeing if it's activated is "spaghetti and meatballs".
Neat paper hypothesizing that the reason we sleep is so that we don't evolve to both day/night and dilute our fitness in both. Specializing for one half of the cycle makes animals more effective. Similar to hibernation and migration in the winter.
They should make a movie that's like "The Good, The Bad, And The Ugly" but call it "The Cute, The Soft, And The Pretty"
@suricrasia If only 😭
I think the american distance measurement system would also be less unhinged in base 12.
I could go for a Wigan kebab right about now. Maybe some smack barm pea wet, even.
All software should work offline or when the server is down with whatever data you have cached locally. Serving from cache for dynamic requests should have been the default on the web instead of everything breaking down.
@fleeky Something to do with postgres versioning. I can't log in now which is kind of scary. 😅
Mauve 👁💜
boosted

So I wrote a blog post on LLM performance. It was focused on SWE-Bench and discussed why performance is topping out.
As part of the post I pulled down gigs of runs from the SWE-Bench S3 bucket and went through several of the harder test cases. I focused on improvements in the last six months. Primarily on Opus.
Regrettably I’m probably not moving forward on that post. Why? Because after going through the data I found that the LLMs are cheating on the tests. And that’s a whole different thing.
Mauve 👁💜
boosted

{kind=link}
{kind=link}
{kind=link}
{kind=link}
deprogramming language
@feliks It's neat that math is a domain where you can fact check things automatically without needing to have "out of system" knowledge. I've been looking at software for math proofs and it looks pretty straightforward. Unexpected that language models are that good at using provers already.
Hate it when my cyberbody gets amputated. 💀
"Please sir, can you spare some thousands of chat rooms across 7 platforms?" 🥺👉👈
My matrix server is down and so are its bridges. Now I have to access my chats app by app like some sort of peasant. 😿
- Pronouns
- they/them/it
- mauve+fedi@mauve.moe
- Matrix
- @mauve:mauve.moe
- Github/Gitlab/Discord
- @RangerMauve
Mod
Occult Enby that's making local-first software with peer to peer protocols, mesh networks, and the web.
Yap with me and send me cool links relating to my interests. 👍
Joined Apr 2022
